🐍 Ausbildung mit Hydra
\
Ein neues Projekt starten
Zuerst müssen wir den Nix-Paketmanager von hier installieren (Mehrbenutzer-Installation).
Die folgenden Schritte sind notwendig, um ein neues Projekt zu erstellen:
- Erstellen einer Nix-Umgebung
- Hinzufügen von Projekt-Abhängigkeiten
- Hinzufügen von Hydra-Jobs
- Schieben und Ausführen
1. Erstellen einer Nix-Umgebung
Wir müssen eine flake.nix (Template)-Datei erstellen und dann git add . und nix develop ausführen, um unsere Umgebung zu betreten, und wir verwenden den Befehl exit, um unsere Umgebung zu verlassen. Die Datei flake.lock wird automatisch erzeugt, um die Versionen der Projektabhängigkeiten zu sperren. Wenn eine Aktualisierung erforderlich ist, können wir den Befehl nix flake update verwenden. Um zu überprüfen, ob unsere Datei auf der Hydra ausführbar ist, überprüfen wir zunächst unsere Umgebung mit dem Befehl nix flake check. Wenn wir ein neues Projekt starten, löschen wir die flake.lock-Datei, um die neuesten Versionen der Abhängigkeiten zu erhalten.
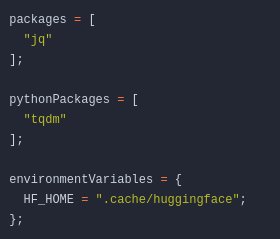
2. Hinzufügen von Projekt-Abhängigkeiten
Da die meisten unserer Projekte Python benötigen, haben wir eine zusätzliche Liste namens pythonPackages, in der wir alle unsere Python-Abhängigkeiten hinzufügen können. Für alle anderen Abhängigkeiten verwenden wir die packages-Liste, um sie hinzuzufügen. Zuletzt können wir alle Umgebungsvariablen in envrionmentVariables-attrset definieren.
3. Hinzufügen von Hydra-Jobs
Es ist notwendig, die Hyperparameter unserer Modelle in eine externe config.json-Datei auszulagern, die in unserem Projektverzeichnis gespeichert wird. Das Projektverzeichnis könnte wie folgt aussehen:
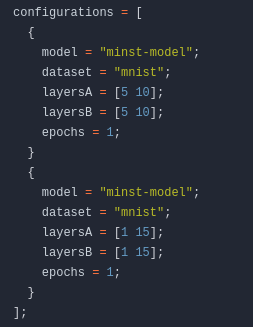
In Zeile 145 können wir alle Hyperparameter definieren, die dann in die config.json-Datei konvertiert werden. Wir verwenden Listen [ /value1/ /value2/ ... /valueN/ ] um unsere json zu permutieren. Mehrere verschiedene config.json Permutationen werden durch Hinzufügen mehrerer configs zum configurations attrset zusammengefasst.
Hashes für den Dateidownload erhalten
Um Datensätze oder andere Online-Ressourcen hinzuzufügen, empfiehlt es sich, diese über Hydra herunterzuladen. Hydra speichert alle Downloads im Cache. Daher müssen wir Online-Dateien nur einmal herunterladen.
Wir definieren eine neue Umgebungsvariable, die den Pfad zum Datensatz enthält, wie folgt:
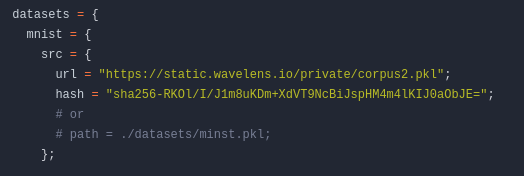
Um sicherzustellen, dass die Dateien gleich bleiben, müssen wir einen Hash angeben. Dies geschieht durch die Ausführung des Befehls: nix hash file [FILE]. Wir können auch sha256-Hashes in sri konvertieren, indem wir nix hash to-sri --type sha256 "[HASH]" ausführen.
4. Pushen und Ausführen
Nachdem wir in unser Git-Repository gepusht haben, müssen wir ein Projekt im Web-Interface von hydra starten.

Wir müssen nur Identifier und Name definieren. 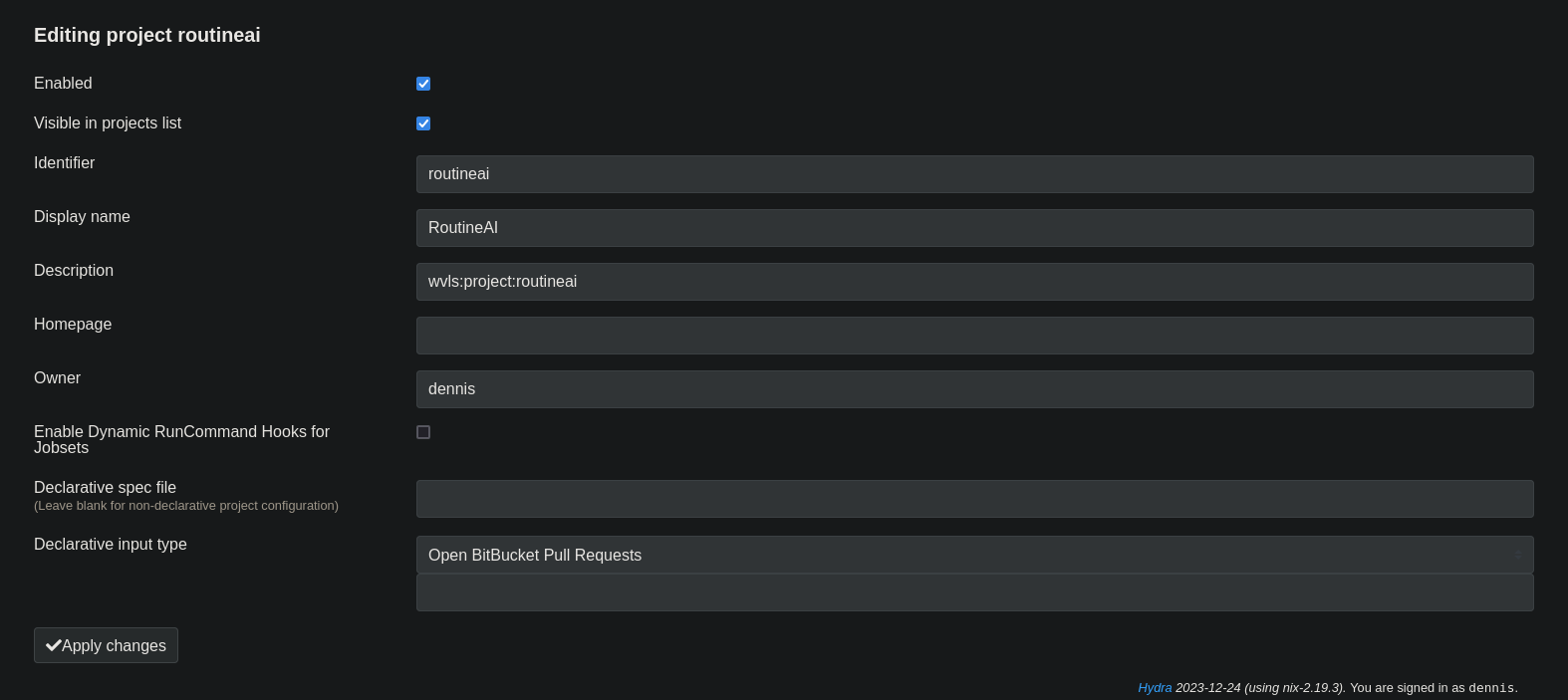
Danach erstellen wir ein neues Jobset im Dropdown-Menü Actions und definieren einen Identifier, setzen die Flake-URI auf unser Git-Repository, das Check interval auf Null, scheduling shares auf 100 und Number of evaluations to keep auf Eins (oder wie viele Modellgenerationen wir behalten wollen).
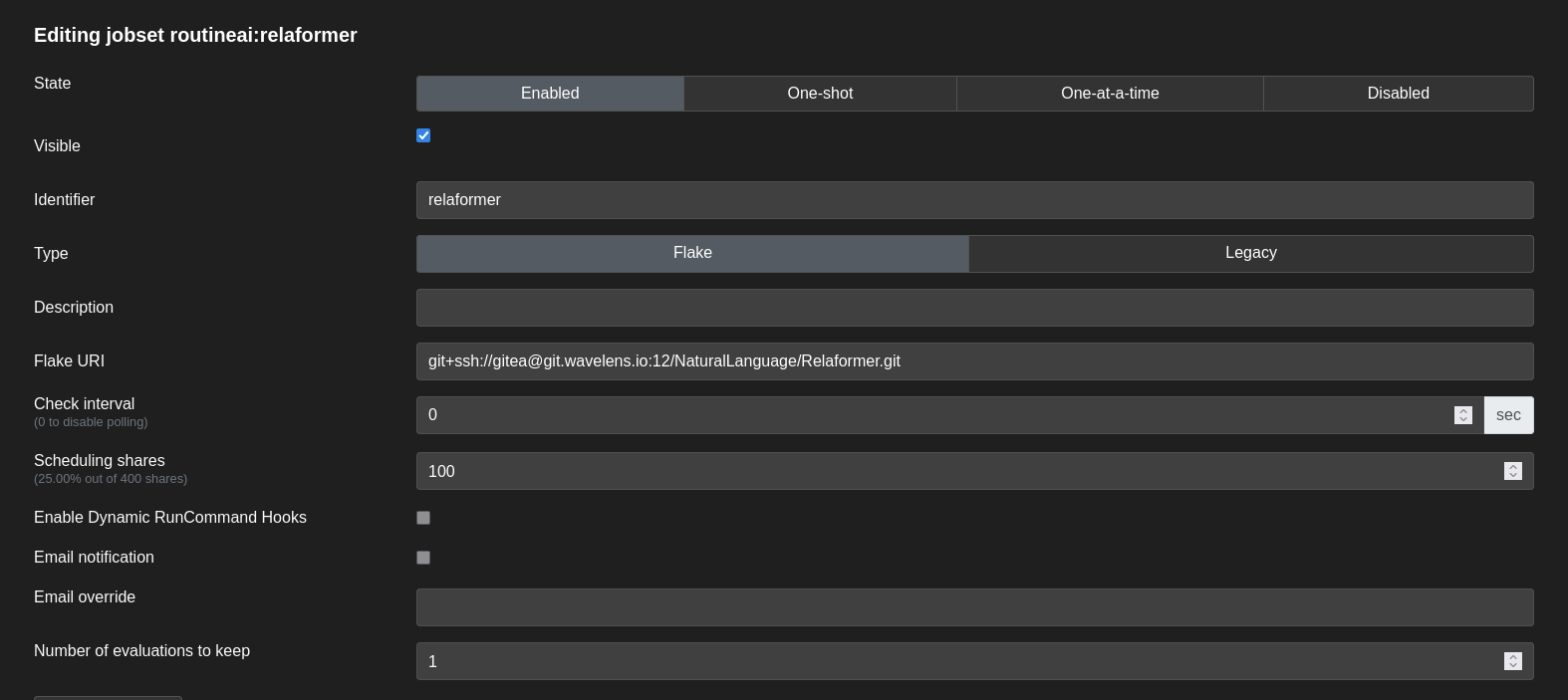
Um unser Jobset auszuführen, klicken wir auf Evaluate this jobset unter dem Actions Dropdown Menü.
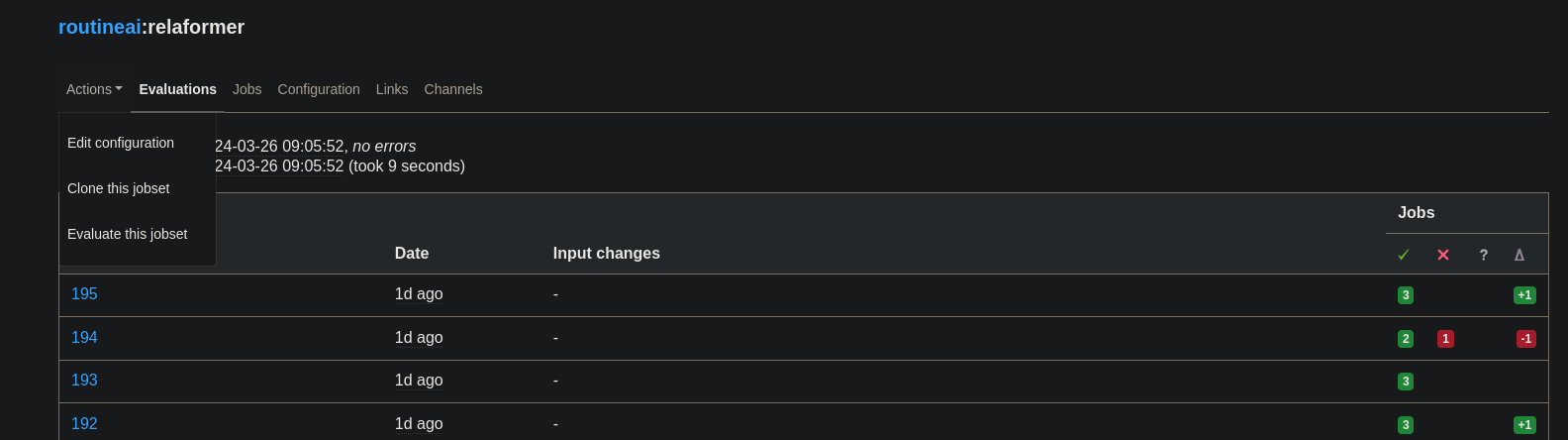
🎉 Glückwunsch, Sie haben jetzt Ihr erstes Hydra-basiertes KI-Training gestartet 🎉